- Trang chủ
-
/ Underfitting là gì? Underfitting khác gì so với Overfitting
Underfitting là gì? Underfitting khác gì so với Overfitting
17/04/2024
15,081 lượt đọc
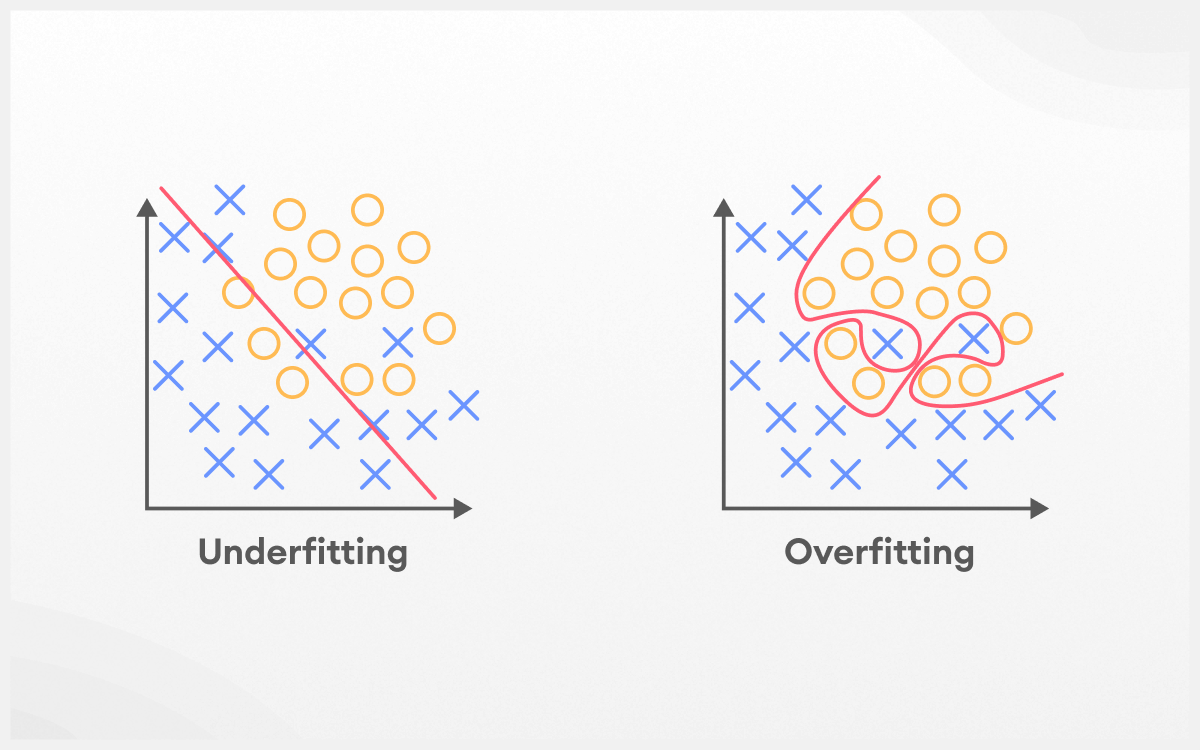
Underfitting (chưa khớp) là hiện tượng khi mô hình xây dựng chưa có độ chính xác cao trong tập dữ liệu huấn luyện cũng như tổng quát hóa với tổng thể dữ liệu. Khi hiện tượng Underfitting xảy ra, mô hình hoạt động kém trên cả dữ liệu huấn luyện và dữ liệu mới vì nó thiếu khả năng tìm hiểu các mối quan hệ phức tạp.
Trong giao dịch thuật toán, underfitting có thể dẫn đến các quyết định đầu tư không hiệu quả vì mô hình không đủ khả năng phân tích và phản ứng với các tín hiệu thị trường phức tạp. Điều này có thể khiến các chiến lược giao dịch dựa trên mô hình này bỏ lỡ những cơ hội lớn hoặc không tránh được rủi ro thị trường.
Nguyên nhân xảy ra hiện tượng Underfitting
- Mô hình quá đơn giản: Đây là nguyên nhân phổ biến nhất của underfitting. Khi mô hình không có đủ độ phức tạp (ví dụ, không đủ lớp hoặc nút trong mạng nơ-ron, hoặc sử dụng một thuật toán quá đơn giản cho một vấn đề phức tạp), nó không thể học hỏi đầy đủ từ dữ liệu.
- Thiếu dữ liệu: Một mô hình có thể không được huấn luyện với đủ dữ liệu, hoặc dữ liệu không đại diện đầy đủ cho toàn bộ không gian vấn đề. Điều này khiến mô hình không có khả năng tổng quát hóa tốt khi gặp dữ liệu mới hoặc khác biệt.
- Đặc trưng không đủ: Mô hình có thể không có đủ thông tin đầu vào hoặc đặc trưng không được chọn lọc kỹ, dẫn đến không đủ khả năng hiểu và dự đoán các mối quan hệ trong dữ liệu.
- Huấn luyện không đầy đủ: Khi thời gian huấn luyện quá ngắn hoặc quá trình huấn luyện không đầy đủ, mô hình cũng có thể không phát triển đủ để hiểu được dữ liệu. Điều này cũng có thể xảy ra do sử dụng các kỹ thuật dừng sớm mà không cân nhắc kỹ.

Làm thế nào để tránh bị Underfitting trong mô hình giao dịch thuật toán
Chọn mô hình phù hợp:
Trong giao dịch thuật toán, việc lựa chọn một mô hình phù hợp với bản chất của dữ liệu là rất quan trọng. Sử dụng mô hình quá đơn giản, như hồi quy tuyến tính cho dữ liệu có mối quan hệ phi tuyến, có thể dẫn đến underfitting, khiến mô hình có độ chệch thấp nhưng phương sai cao. Để giải quyết vấn đề này, các nhà giao dịch nên lựa chọn mô hình phù hợp với đặc tính và phân phối của dữ liệu, có khả năng xử lý các đặc điểm và tương tác liên quan đến nhiệm vụ dự đoán. Việc so sánh các mô hình khác nhau bằng cách sử dụng các chỉ số như R bình phương, sai số bình phương trung bình hoặc độ chính xác là cần thiết để chọn ra mô hình tối ưu nhất cho giao dịch thuật toán.
Việc lựa chọn mô hình không chỉ dựa trên hiệu suất mà còn cần đảm bảo rằng mô hình có khả năng thích ứng và tổng quát hóa tốt trên dữ liệu mới, không chỉ tối ưu trên dữ liệu lịch sử mà còn hiệu quả khi áp dụng vào giao dịch thực tế.
Giảm bớt điều chỉnh (Regularization)
Điều chỉnh (Regularization) là một phương pháp thường được áp dụng trong xây dựng mô hình học máy để giảm thiểu biến động của mô hình, bằng cách đưa ra hình phạt cho các tham số đầu vào có hệ số lớn. Các kỹ thuật điều chỉnh khác nhau như L1, Lasso hay dropout được sử dụng để làm giảm nhiễu và loại bỏ các điểm dữ liệu ngoại lai khỏi mô hình. Tuy nhiên, một vấn đề có thể xảy ra khi áp dụng điều chỉnh quá mức là làm cho các đặc điểm dữ liệu trở nên quá đồng nhất, khiến mô hình không còn khả năng phát hiện được xu hướng chủ đạo của dữ liệu. Điều này có thể dẫn đến tình trạng underfitting, nơi mô hình không đủ phức tạp để hiểu đúng bản chất của dữ liệu. Bằng cách giảm bớt mức độ điều chỉnh, chúng ta có thể giới thiệu thêm độ phức tạp và biến động vào mô hình, từ đó cải thiện khả năng huấn luyện và hiệu suất của mô hình.

Tăng thời gian huấn luyện
Việc kết thúc quá trình huấn luyện sớm có thể dẫn đến tình trạng underfitting, khi mô hình chưa đủ “thời gian” để “học” hết các mẫu trong dữ liệu. Do đó, việc kéo dài thời gian huấn luyện có thể giúp tránh được tình trạng này, cho phép mô hình phát triển đầy đủ khả năng của mình. Tuy nhiên, điều cực kỳ quan trọng cần lưu ý là cần tránh tình trạng huấn luyện quá mức, hay còn gọi là overfitting, nơi mô hình quá phù hợp với dữ liệu huấn luyện mà mất đi khả năng tổng quát hóa trên dữ liệu mới. Việc tìm kiếm một sự cân bằng giữa huấn luyện đủ và quá mức là chìa khóa để đạt được hiệu suất tối ưu.
Lựa chọn đặc điểm
Các đặc điểm dữ liệu được lựa chọn cho mô hình cần phải phản ánh đúng các yếu tố ảnh hưởng đến thị trường. Trong giao dịch thuật toán, việc bổ sung các đặc điểm mới hoặc cải thiện chất lượng của các đặc điểm hiện tại (ví dụ, thông qua kỹ thuật tạo đặc điểm mới) có thể giúp mô hình phát hiện tốt hơn các mẫu thị trường và cải thiện khả năng dự đoán.
Ví dụ, trong một mạng nơ-ron, có thể tăng số lượng nơ-ron ẩn hoặc trong một mô hình rừng ngẫu nhiên, có thể tăng số lượng cây để thêm độ phức tạp và cải thiện khả năng dự đoán của mô hình.

Sự khác biệt giữa Underfitting so với Overfitting
| Khía cạnh so sánh | Mô hình Underfitting | Mô hình Overfitting |
| Loại mô hình | Mô hình quá đơn giản | Mô hình quá phức tạp |
| Độ chính xác | Không chính xác cho cả tập huấn luyện và tập kiểm thử | Chính xác cho tập huấn luyện nhưng không cho tập kiểm thử |
| Chỉ báo | Độ chệch cao do không học đủ, phương sai thấp vì thiếu đa dạng | Lỗi huấn luyện do học quá kỹ và phương sai cao do phức tạp quá mức |
| Phát hiện | Dễ nhận biết thông qua lỗi lớn khi huấn luyện và kiểm thử | Khó phát hiện hơn mô hình underfit nhưng được chẩn đoán khi lỗi huấn luyện thấp và lỗi kiểm thử/kiểm định cao |
| Cách giải quyết | Mô hình phức tạp hơn, giảm bớt điều chỉnh, thêm nhiều đặc trưng | Mô hình đơn giản hơn, tăng điều chỉnh, giảm số lượng đặc trưng |

Đánh giá
0 / 5